"Entities must not be multiplied beyond necessity." — The Principle of Ockham's Razor
Large Language Models (LLMs) such as GPT-4, Claude 3, and Gemini have demonstrated remarkable capabilities in complex problem-solving, largely attributed to their advanced reasoning abilities. Techniques like Chain of Thought (CoT) prompting and self-reflection have become central to this success, enabling models to perform step-by-step deductions for tasks requiring deep knowledge and logical rigor. However, as the industry increasingly emphasizes this "long decoding" mode, the computational cost associated with these reasoning processes has grown significantly.
While LLM evaluation and comparison have become increasingly important, most evaluations focus primarily on accuracy while the efficiency of generation is less discussed. For example, HELM, LM-Eval, and the LMSYS Chatbot Arena rank models almost entirely on task accuracy. Yet in real systems, the difference between generating 10K tokens vs 100K tokens is non-trivial in latency, cost, and energy.
We introduce OckBench, the first model-agnostic, hardware-agnostic benchmark that jointly measures accuracy and decoding token count for reasoning and coding tasks. Our key contributions include:
Model-Agnostic Efficiency Metric: We formalize decoding token count as an intrinsic, hardware- and system-independent efficiency metric
Efficiency-Accuracy Aware Benchmark: The first unified benchmark specifically designed to evaluate LLM reasoning efficiency by measuring token consumption alongside accuracy
Empirical Trade-offs: We conduct experiments across multiple open- and closed-source models, revealing substantial practical trade-offs on the accuracy–efficiency Pareto frontier
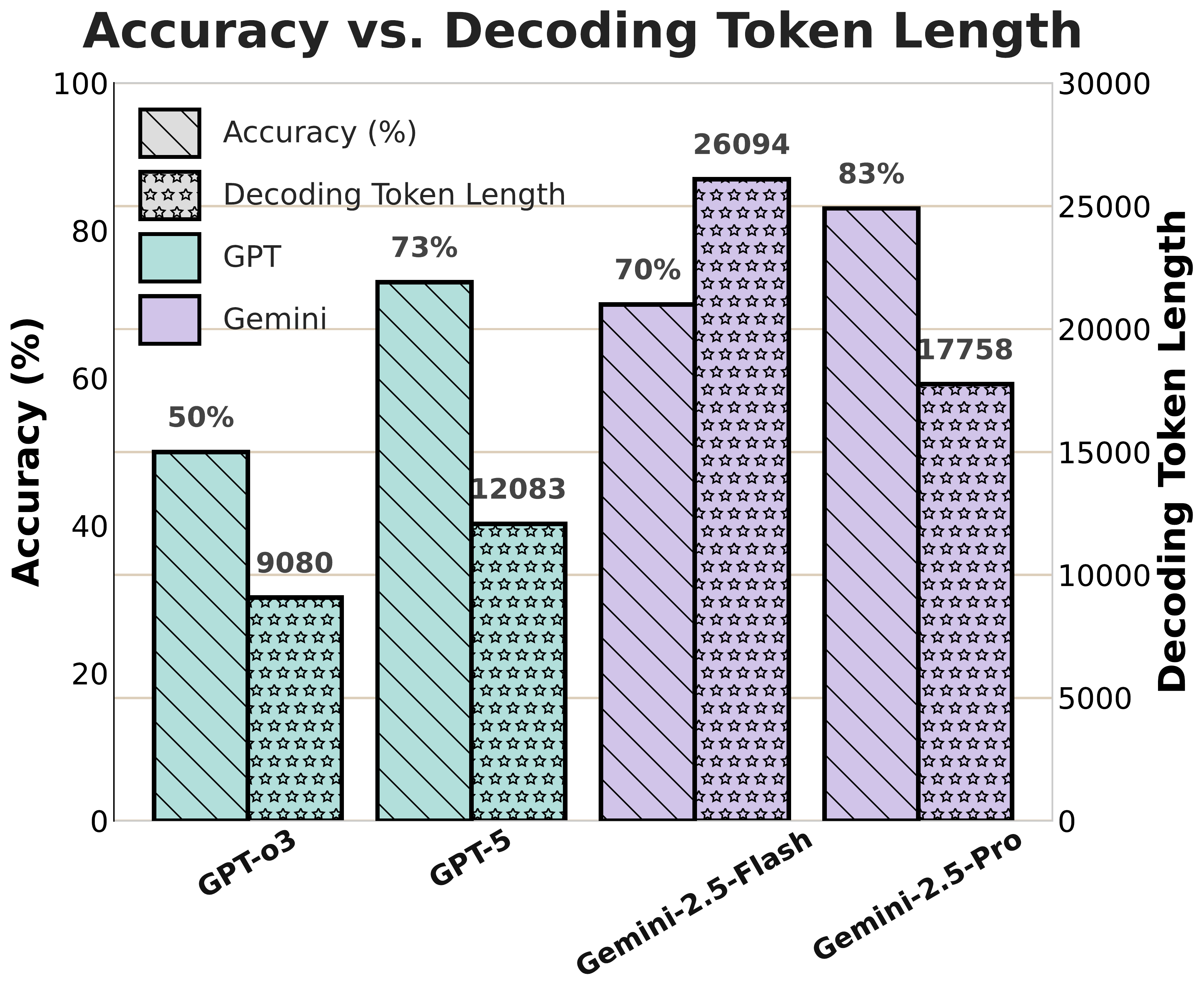
Through experiments comparing multiple open- and closed-source models, we uncover that many models with comparable accuracy differ wildly in token consumption. For instance, among commercial models, one high-accuracy model required over 2× the tokens of another to achieve similar accuracy. This reveals that efficiency variance is a neglected but significant axis of differentiation in LLM evaluation.
Commercial models with similar performance level but spent token budget differently
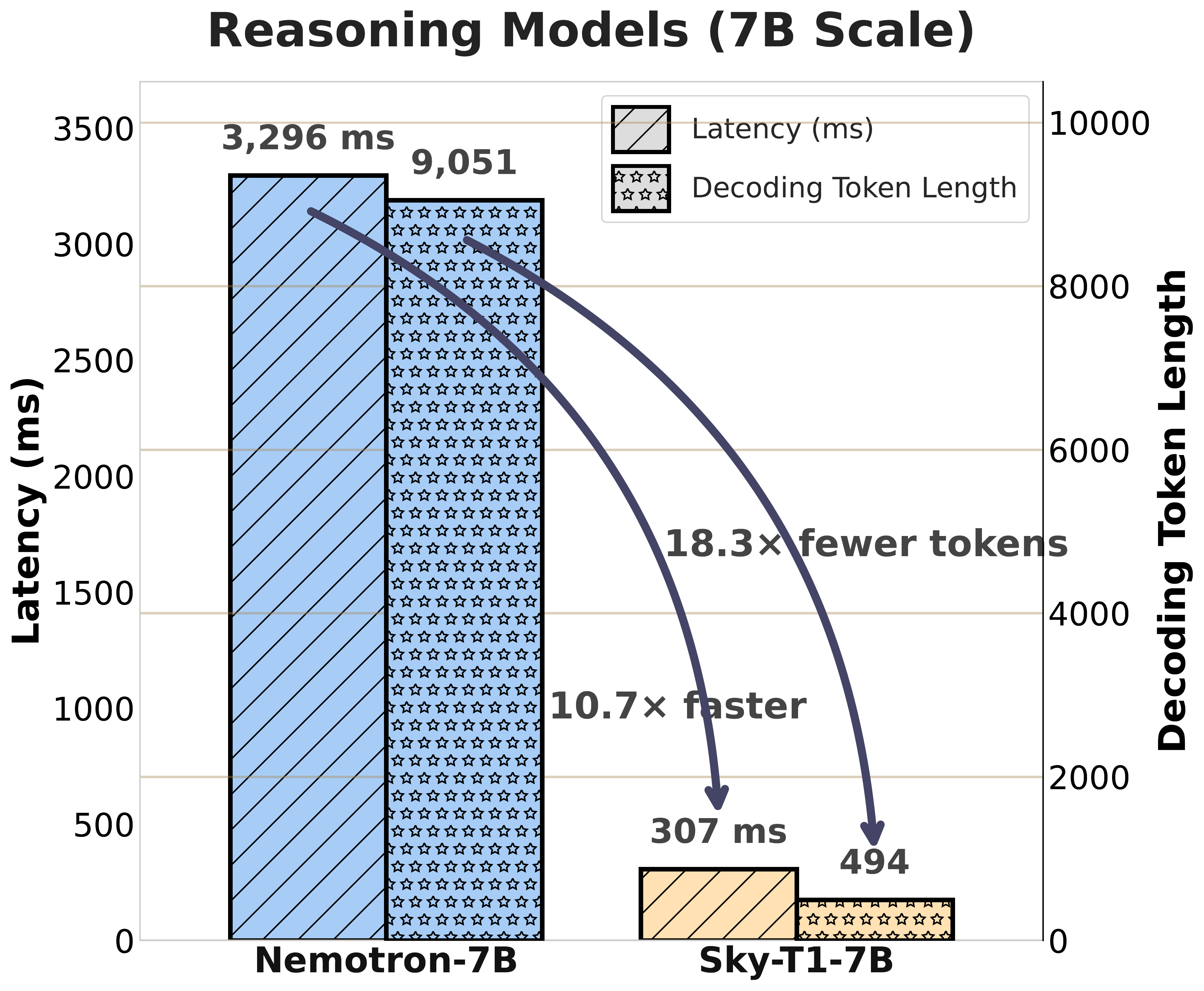
Similar model size but takes drastically different time in reasoning tasks
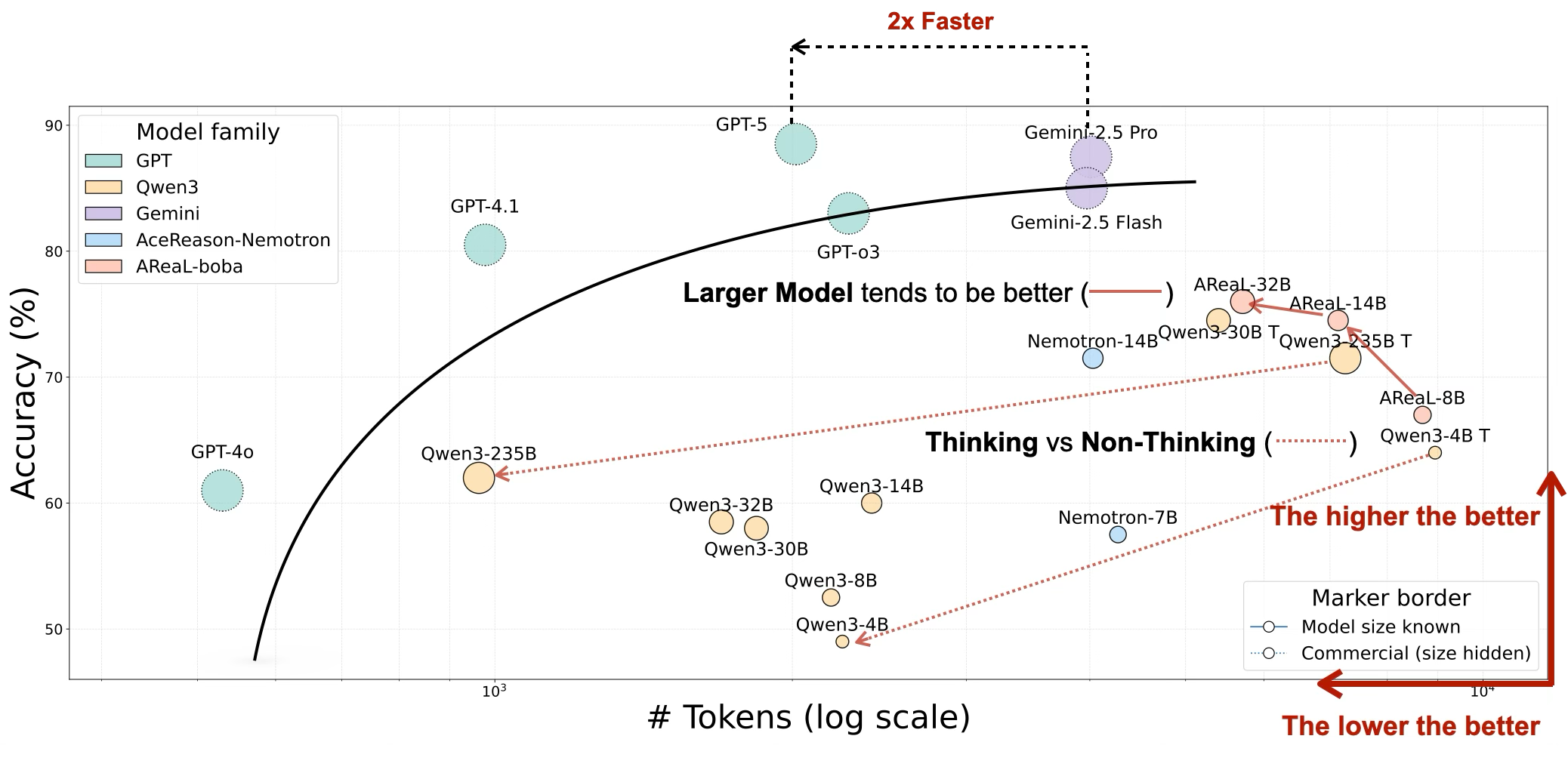
Accuracy vs. token consumption trade-off analysis across dense and refined reasoning models, demonstrating the efficiency frontier for different model configurations
Leaderboard
Performance of various LLMs on OckBench. Models are ranked by their reasoning efficiency,
which is computed as #Tokens / Accuracy (lower is better). Click on the tabs to switch between Math and Coding domains.
OckBench provides comprehensive evaluation across multiple dimensions
Total Questions
400
Task Domains
2
Questions per Domain
200
Models Evaluated
24
Benchmark Composition
OckBench is structured to test LLMs' reasoning efficiency across two complementary domains: mathematical problem solving and coding skills. To better expose token-efficiency differences, we select questions that exhibit high variance in decoding token usage among baseline models.
Mathematics and Reasoning Tasks (200 questions): We adopt GSM8K, AIME24, and AIME25 as core reasoning benchmarks. We select the top 200 questions that exhibit high variance in decoding token usage among baseline models, ensuring the benchmark emphasizes efficiency contrast rather than merely ranking by accuracy.
Software Engineering Tasks (200 questions): For the coding domain, we build a lightweight variant of MBPP, supplemented by 200 carefully curated real-world coding problems. These coding tasks cover algorithmic challenges, code transformation, debugging, and small-scale project tasks.
Example Tasks
Sample problems from OckBench-Math and OckBench-Coding
These examples illustrate the types of problems where token efficiency varies significantly across models.
Math Problem (GSM8K)
Question: A store sells notebooks for $3 each. If you buy more than 10, you get a 20% discount on the total price. How much would it cost to buy 15 notebooks?
Domain: Mathematics | Source: GSM8K
Token variance: Some models use 200 tokens, others use 2,000+ for the same answer.
Math Problem (AIME)
Question: Find the number of ordered pairs (a,b) of integers such that a² + b² = 2024 and both a and b are positive.
Domain: Mathematics | Source: AIME 2024
Token variance: High variance across models due to different reasoning approaches.
Coding Problem (MBPP)
Task: Write a function to find the longest common subsequence of two strings. For example, lcs("ABCDGH", "AEDFHR") should return 3 (the LCS is "ADH").
Domain: Coding | Source: MBPP variant
Token variance: Efficient models write concise code with brief explanations.
Future Work: More Domains
Planned Extension: We plan to extend OckBench to additional domains such as algorithmic challenges, debugging tasks, and code transformation problems to provide more comprehensive token efficiency evaluation.
Status: Coming in next version | Focus: Broader coverage
Stay tuned for expanded benchmark coverage across more reasoning domains!
Key Findings
2× token variance among top models: Gemini-2.5 Pro used 2× more tokens than GPT-5 for similar accuracy (5,198 vs 2,336 tokens).
GPT-4o is most token-efficient: Best reasoning efficiency of 14.1 (math) and 12.9 (coding) despite lower accuracy.
"Thinking" modes costly: Qwen3-14B thinking used 2.7× more tokens than non-thinking (8,190 vs 3,010) without proportional gains.
Commercial models lead: 60.8% average accuracy vs 35.3% for open-source on math tasks.
10-18× efficiency differences: Models with comparable accuracy differ wildly in token consumption.
Size doesn't guarantee efficiency: Smaller models sometimes use more tokens than larger ones for the same tasks.
Citation
If you find OckBench useful for your research, please cite our work
@inproceedings{du2025ockbench,
author = {Du, Zheng and Kang, Hao and Zhu, Ligeng and Han, Song and Krishna, Tushar},
title = {OckBench: Tokens are Not to Be Multiplied without Necessity},
booktitle = {NeurIPS 2025 Workshop on Efficient Reasoning},
year = {2025}
}
 OckBench
OckBench