Zheng Du1*, Hao Kang1*, Song Han2, Tushar Krishna1, Ligeng Zhu3
*Equal contribution
1Georgia Institute of Technology ·2MIT ·3NVIDIA
1. Introduction
“Entities must not be multiplied beyond necessity.”
— The Principle of Ockham’s Razor
Large Language Models (LLMs) like GPT-5, Gemini 3, and Claude serve as the frontier of automated
intelligence, fueled by reasoning techniques like Chain of Thought (CoT). As the field embraces
test-time compute scaling, models are increasingly trained to generate extensive token chains to
tackle tougher problems. However, this massive inflation of decoding tokens introduces a critical
bottleneck: solving just six problems in the International Olympiad in Informatics can now take
over ten hours, and complex mathematical challenges frequently explode into millions of tokens.
While the community celebrates gains in reasoning capability, prevailing benchmarks like HELM and
Chatbot Arena focus almost exclusively on output quality, ignoring this token efficiency
crisis. In reality, many models consume vastly more tokens than necessary to reach the
correct answer. Two models reaching the same accuracy can differ by more than
25× in tokens generated — one answering in ~1,600 tokens where another
spends ~42,000. As accuracy on standard tasks approaches saturation, tokens must be treated as a
cost — not a free resource.
We introduce OckBench, the first model- and hardware-agnostic benchmark that
jointly measures accuracy and token efficiency. Our key contributions include:
Per-Token Intelligence. We introduce a new evaluation dimension — a superior model must not only achieve high accuracy but do so with minimal token consumption.
OckBench & OckScore. A benchmark with a novel Differentiation Filter that isolates tasks exposing the efficiency gap, paired with a unified metric that rewards high accuracy achieved with fewer tokens.
The Overthinking Tax. We formally quantify how smaller models often incur paradoxically higher deployment costs due to excessive verbose reasoning chains.
Optimization Pathways. We demonstrate that efficiency is tractable — both training-free model interpolation and difficulty-aware RL significantly improve OckScore.
Through extensive evaluations on 56 frontier and open-source model
settings, we find that top open-source models have nearly closed the accuracy gap but consume up to
26× more tokens than commercial counterparts for comparable accuracy.
Meanwhile, frontier commercial models are rapidly co-optimizing both dimensions, validating
Per-Token Intelligence as the next key axis of LLM evaluation.
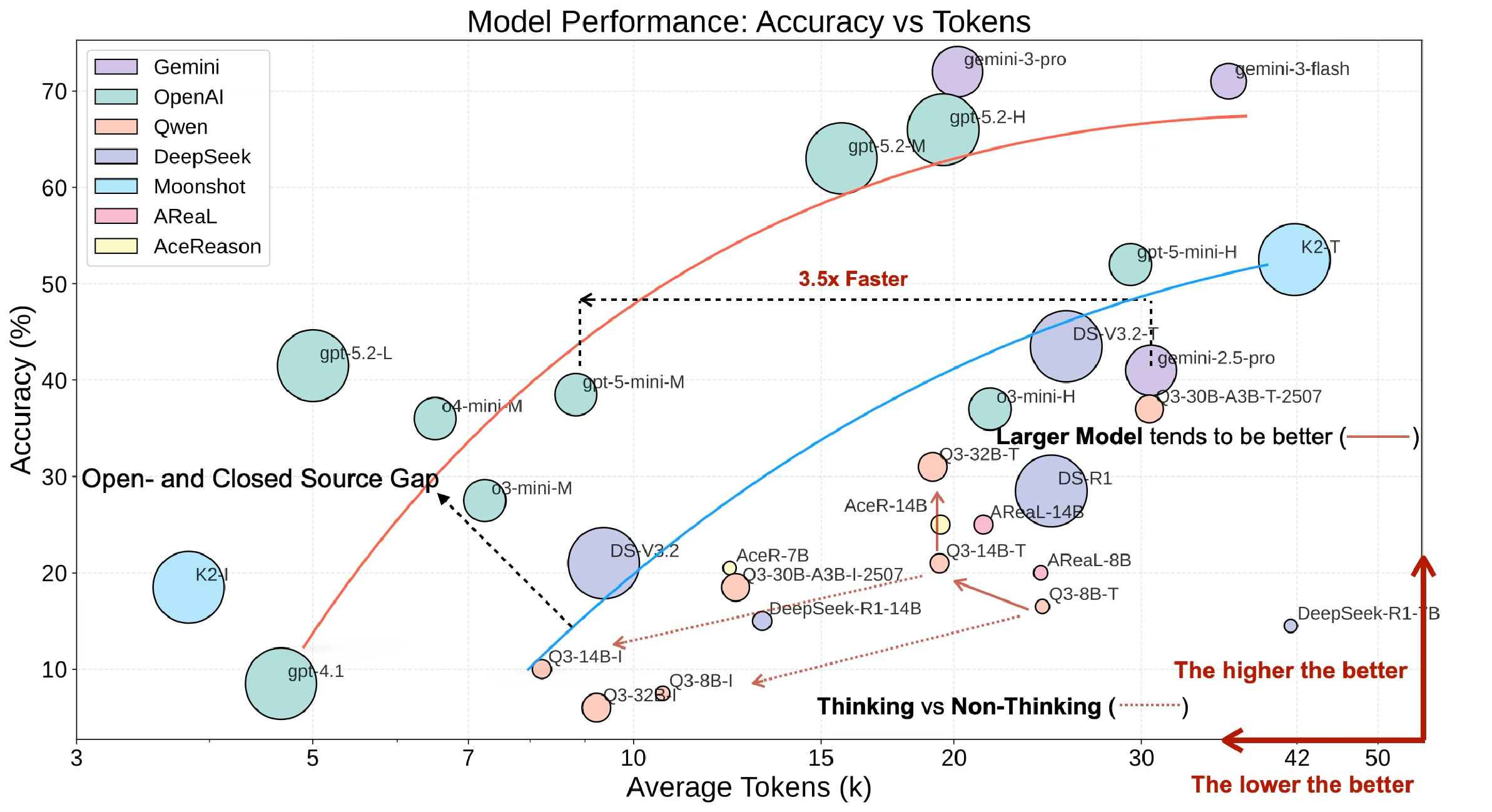
Figure 1. Accuracy vs. Average Tokens across
56 evaluated model settings. Models in the upper-left corner are
ideal. The Pareto frontier is dominated by commercial models; open-source models cluster to the right.
Three observations
Closed models own the frontier
Claude Opus 5 (high) leads at 88.84 OckScore. Its xhigh setting follows at 88.20 with the table’s highest accuracy, 95.0%, while max ranks third at 86.11.
Open vs. closed gap
Kimi-K3 (high) remains the leading open-weight setting at rank 13. Claude Opus 5 (high) is 6.5 percentage points more accurate while Kimi uses 1.8× more tokens (12,250 vs 6,745).
Effort trade-offs
Claude Opus 5 (xhigh) gains one accuracy point over high, but uses 1.44× more tokens and scores lower. Max uses 1.95× the tokens of high for only 0.5 points more accuracy.
2. Leaderboard
Performance of various LLMs on OckBench (Selected) — 200 problems
(100 math + 60 coding + 40 science). Models are ranked by OckScore
= Accuracy − 10 × ln(AvgTokens / 10,000 + 1) — higher is better. Sampling follows
each model’s validated evaluation configuration, and math accuracy is graded by an LLM judge.
MiniMax-M2.7 is the equal-weight pooled average of four InfiniAI requested effort-label runs
(800 model-problem observations). Opus 5 (medium) includes nine persistent zero-output
generation failures (eight coding and one science); they count as incorrect and are excluded
from the average-output-token denominator, as are all error rows.
Figure 2. Accuracy vs. average output tokens (log scale) for
the settings currently shown in Table 1 — it follows the same filter and toggle.
Color marks the model family; filled marks are commercial models, hollow marks open-source.
The dashed hairline traces the Pareto frontier (the best accuracy attainable at a given token
budget); faint hairlines connect effort variants of the same model. Hover a point — or a
row of the table — to cross-highlight.
Table 1. Accuracy, average output tokens, and OckScore for all evaluated model settings, ranked by OckScore.
#
Model
License
Avg Tokens
Accuracy (%)
OckScore
Click a numeric column heading to sort; higher OckScore is better.
––
Model
Math
Coding
Science
Figure 3. Per-domain accuracy for the settings currently
shown in Table 1 — the grid follows the same filter, toggle, and column sorting.
Darker cells mark higher values; switch to Avg Tokens for a log-mapped token view. Hover a
cell for the exact figures, or a row to cross-highlight with the table.
3. The Benchmark
OckBench provides comprehensive evaluation across multiple dimensions.
200Questions per domain
3Task domains
8+Source datasets
56Settings evaluated
Benchmark composition
OckBench aggregates tasks across three complementary reasoning domains. Rather than random
sampling, we apply the Differentiation Filter: selecting problems where accuracy
across models falls within 10%–90% (avoiding floor/ceiling effects) and token variance is
maximized — isolating instances that reveal intrinsic efficiency differences.
Math 100
Coding 60
Science 40
Mathematics & Reasoning. GSM8K, AIME 2024/2025, OlympiadBench, MATH500, AMO-Bench, and the mathematics subset of Humanity’s Last Exam — spanning grade-school arithmetic to competition-level number theory.
Software Engineering. A lightweight variant of MBPP and LiveCodeBench, assessing practical code generation and planning skills verified via unit test execution.
Scientific Reasoning. ScienceQA, MMLU (STEM subsets), and GPQA-Diamond, testing knowledge-constrained reasoning and concision under technical load.
4. Example Tasks
Sample problems from OckBench’s math, coding, and science domains. These examples illustrate the types of problems where token efficiency varies significantly across models.
Example 1Mathematics · GSM8K
A store sells notebooks for $3 each. If you buy more than 10, you get a 20% discount on the total price. How much would it cost to buy 15 notebooks?
$3 × 15 × 0.8 = $36 — a 3-second mental calculation. Yet some reasoning models spend 2,000+ tokens setting up formal equations, double-checking edge cases, and re-reading the problem before arriving at the obvious answer.
Example 2Mathematics · AIME 2024
Find the number of ordered pairs (a,b) of integers such that a² + b² = 2024 and both a and b are positive.
Efficient models notice 2024 = 4 × 506 and apply modular arithmetic to eliminate large search spaces in a few steps. Verbose models enumerate all 44² candidate pairs one by one — correct eventually, but at 10× the token cost.
Example 3Coding · MBPP variant
Write a function to find the longest common subsequence of two strings. For example, lcs(“ABCDGH”, “AEDFHR”) should return 3 (the LCS is “ADH”).
A clean DP solution is ~10 lines. But many models first write a recursive solution, identify the redundancy, rewrite with memoization, then pivot to bottom-up — producing correct code buried under 800 tokens of self-tutoring.
Example 4Scientific Reasoning · GPQA-Diamond
A molecule undergoes a photochemical reaction in which it absorbs a photon and transitions to an excited state. If the excited state has a lifetime of 10 ns, what is the natural linewidth (in Hz) of the corresponding spectral line?
Efficient models recall Δν = 1/(2πτ) and plug in τ = 10 ns for an instant answer. Overthinking models re-derive the time-energy uncertainty relation from first principles — impressively thorough, but it is a textbook formula lookup.
5. Key Findings
Closed models own the efficiency frontier. Claude Opus 5 takes the top four positions with high, xhigh, max, and low. High leads at 88.84 OckScore; xhigh reaches the table’s highest accuracy, 95.0%, at 88.20 OckScore. The top 12 settings are closed models, with Kimi-K3 (high) the first open-weight entry at rank 13.
The open-source efficiency gap remains. Claude Opus 5 (high) reaches 94.0% accuracy with 6,745 average output tokens, while open-weight leader Kimi-K3 (high) reaches 87.5% and uses 1.8× more tokens. Their OckScores differ by 9.34 points (88.84 vs 79.50).
The Overthinking Tax. In the Qwen3.5 family, larger models are both smarter and leaner — Qwen3.5-9B burns 116,222 tokens for 21.5% accuracy (last place at OckScore −3.85), while Qwen3.5-397B-A17B reaches 67.5% using 4.4× fewer tokens. Smaller models over-generate to compensate for lower capacity.
More effort is not monotonically efficient. Claude Opus 5 peaks in OckScore at high. Xhigh gains one accuracy point but uses 1.44× more tokens, while max uses 1.95× the tokens of high for only 0.5 points more accuracy; their OckScores fall to 88.20 and 86.11.
Kimi-K3 raises the open-weight bar. At 87.5% accuracy, 12,250 tokens, and 79.50 OckScore, Kimi-K3 (high) gains 3.5 accuracy points over the previous open-weight leader, DeepSeek-V4-Pro (high), while using 3.6× fewer tokens and gaining 12.30 OckScore points.
MiniMax-M2.7 is reported as a repeated-run average. Its row pools minimal/low/medium/high requested labels to 66.875% accuracy, 35,538 average output tokens, and 51.72 OckScore. The labels were accepted by the gateway but are not presented as a verified reasoning-depth ladder.
6. Citation
If you find OckBench useful for your research, please cite our work.
@article{du2025ockbench,
title={OckBench: Measuring the Efficiency of LLM Reasoning},
author={Du, Zheng and Kang, Hao and Han, Song and Krishna, Tushar and Zhu, Ligeng},
journal={arXiv preprint arXiv:2511.05722},
year={2025}
}